ChatGPT vs. Stack Exchange

One big reason places like Wikipedia and Stack Exchange became so amazing is that they have developed a very tight culture of quality: although it's true that anyone can contribute, in reality every entry is relentlessly filtered, edited and reviewed by a core group of committed contributors.
In the early days of the WP it was possible to append some nonsense to an existing article, and even (gasp!) start a new article with content of very poor quality. Those edits could stay unchanged for a very long time, and so it was relatively common to stumble upon pages filled with illegible stuff or including made-up gibberish without sources or external links. I know that because almost two decades ago I contributed a little for the first time to a couple articles (like “Granada”), and the few sentences I added stuck for months or years (not that I trolled or wrote anything false).
On the other hand, my recent (little) experience trying to contribute to WP articles has been less sweet. In the last years I have fixed typos and grammatical errors without any problem. However, when it comes to starting a new page or adding more than a few words to existing ones, I find that rules and etiquette are so stringent now that they raise the bar way above the time I can spend on a WP page as a quick distraction from work or whatever I am doing at the time, and so my edits have been sometimes questioned or reverted.
Ditto about Stack Overflow and all the other sites of the SE family. I remember well the refreshing feeling when Atwood & Spolsky launched the thing: it was bold, easy, incredible quality and very helpful. It's still all those things… but for the “easy” part. Today it's so easy to misstep (asking or answering a question) that sometimes it can be intimidating. “Too short”, “too long”, “answered elsewhere”, “add fewer tags”, “should provide and example”, etc.
(As I said at the beginning: I know I shouldn't complain, because those high bars and the incredibly serious army of contributors is precisely what makes those sites high quality, useful, and mostly reliable.)
Anyway, I was reminded of all that last week when I read about ChatGPT.
As with previous deep learning models (I'll say more about them later),
I immediately felt the desire to play with ChatGPT.
And it being an OpenAI product, I knew I had access already.
(If you too have an OpenAI account, head to chat.openai.com/chat now.)
Looking at that prompt blinking on my browser (it doesn't blink, but I like the dramatic effect), I tried to think of interesting questions to ask the Oracle. I wanted something actually useful to me, but not too easy. What do I want to know, really?
Then I remembered that I had recently posted two questions on SE sites, that one had been closed (because it “needs to be more focused”) and that for the other one I didn't feel I got the information I wanted from the handful of responses (generous and well-intentioned as they were). That was perfect for ChatGPT: two recent genuine questions of mine that had received no satisfactory answer from humans.
As part of my ongoing quest to read, implacably and without exceptions, the top forty or so of all the best books ever written, I am currently ploughing through Marcel Proust's “In Search of Lost time”. Specifically, I'm now getting to the end of the third volume, “The Guermantes Way”, 1,600 pages or so deep into the series. Something that I've wondered often is how much of what I see on the page is the life experience of the author, and how much is made up. I don't need to tell you that being a ~4,200-page-long seven-volume novel, there is incredible detail and hundreds of characters. I knew from the beginning that Proust wrote it in part as a recollection of his own memories, but quite often I'm itching to know exactly what juicy events and fascinating characters were real, and what are products of his fantasy.
I asked that on Literature Stack Exchange, but my post got no answers nor comments (although it was upvoted a few times).
Last week I tried my hand with ChatGPT pasting the same question verbatim:
“How much of ‘À la recherche du temps perdu’ is autobiographical?”
Thus Spoke The Oracle:

Nice! I guess software is always software, no matter how cutting-edge or sophisticated. (I should note I got this response two or three times during our entire “dialogue”.)
It was classic “did you unplug it?”, so I simply pressed enter at the prompt again to resubmit the same line.
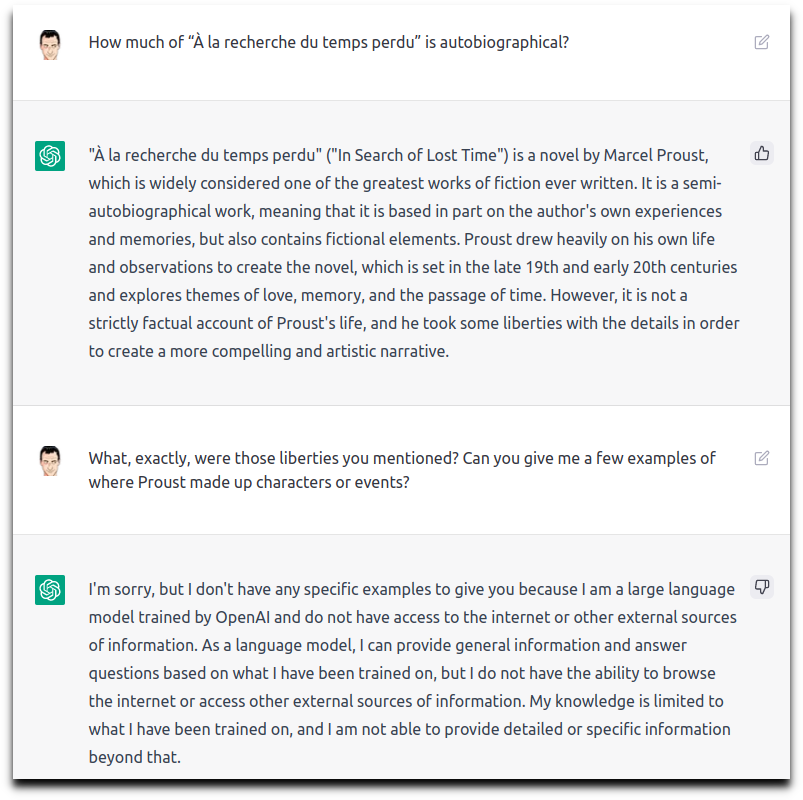
The first answer was basically telling me that yes, it's partly autobiographical and partly fiction. But that's more or less what I knew already and what one can surmise by skimming a WP article or an intro to the novel. And that one bite of information came wrapped in elegant factoids that do nothing to answer my specific question and that I knew, too (the name of the author, the themes he explores, etc).
When I pressed for details, the response was even more disappointing (“yeah, I'm just a conversational bot, I don't really know stuff nor can I look it up on the internet”).
Not great.
OK, another simple curiosity of mine of recent times: I have been frustrated by partisan and short-sighted administration of public pension plans in my country, Spain. (I think I am not alone in that!) In particular, I'm worried that public pension funds and the monthly stipends that our governments dole out are out of sync, unrealistic, and unsustainable: there is population stagnation at best (likely decline) and a constant increase in life expectancy, and our fiscally irresponsible governments keep on piling public debt.
Me having a libertarian bent, the question I keep on shouting at everyone (very quietly in my head) is: why on Earth are we imposing this unjust debt on our kids and grandkids, collectively spending our public retirement funds now, and trusting that future taxpayers will generate sufficient surplus to pay for the pensions that we today deem fair for us? Why don't we save and invest all that money instead, and accumulate assets that make up for the liability that is our getting old? I understand that for politicians it's simply better to mount even more debt and pass the issue to the next generation — but would it be economically feasible for a state to actually save that money for the future, or is there some basic rule of Economics that makes that impossible in practice?
I formulated it as such on Stack Exchange Economics:
“Is it possible that pensions (public or private) be actual money saved and ‘sent’ into the future, instead of borrowed from future generations?”
But as I mentioned, my post was closed because it “needs to be more focused” (even when there's a body of context under the title) — and closed again after I edited and resubmited it. So, zero answers.
Cue in ChatGPT:
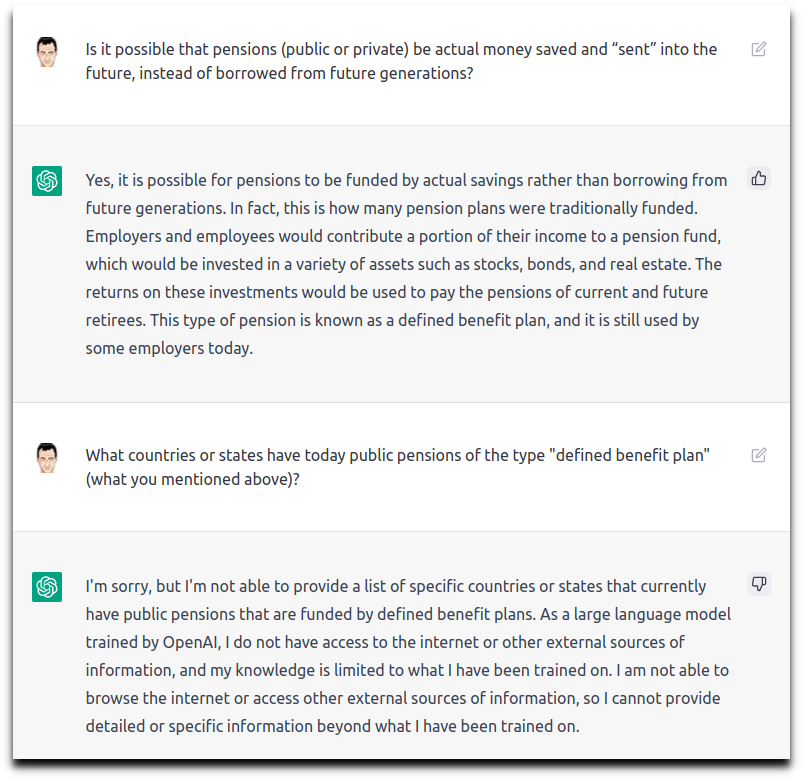
That seemed somewhat useful. The Oracle answered “yes” to my question, and put a name on what was in my head: “defined benefit plan”. It also hinted that many pension plans actually used to be of that type.
Unfortunately, when I scan the corresponding WP page, I have the impression that a pension plan does not need to be based on assets saved/invested now (instead of taxes collected in the future) to be considered “defined benefit”, and so the crux of my question was ignored.
And my attempt to get an actual example of a country with such system in place was met with the usual helpless boilerplate.
Again, not great.
OK, last query.
This is a private joke that only a handful of close friends will get (but it's still a clear question with a definite answer):

Tsk, tsk. ChatGPT suggested only a few possibilities, and some of those were long shots (who would write “momona” instead of “momentum”?). And it needed a big clue from me to get to the answer, which in this case I already knew. (Admittedly, “momona” is very slangy, and I suspect a majority of native speakers in Spain would not understand it, especially stripped of any context.)
At that point I felt bad for ChatGPT. The Oracle was trying rhis best, and I wasn't even paying vhim. I switched to thankful-nonetheless/encouragement mode:
Sigh.
By sheer coincidence, last week I listened to the beginning of a podcast episode with Stephen Wolfram, and I got reminded of WolframAlpha. A few years ago, WolframAlpha was supposed to be the Oracle. I played with that one too, back then. Whatever happened to rher?
Well… WA turned out to be even worse at answering my questions. See vher answers to the Proust question; to the pensions questions; to what countries have “defined benefit plan”. In fact, WA's responses look more like DuckDuckGo's “instant answers” — and not even very good ones — than like intelligent human answers. eg: “here's all the volumes that make up ‘In Search of Lost Time’ and their publication dates”; or: “you said ‘into the future’; here's the cast and roles of the film ‘Il Futuro’”; etc.
Thinking also about the deep learning software for image generation that I have tested
(DALL·E, Midjourney, DALL·E Mini Craiyon),
I have the impression that each model excels at a certain type of work: Midjourney is great for photorealistic illustration and
cyberpunk art, Dall·E sucks (probably by design) at rendering human faces, they all suck at
painting banners and captions, etc.
I suspect ChatGPT is really useful for brainstorming, to generate ideas and drafts, and to find sufficiently good answers to certain kinds of narrow questions. In my very limited experience, it isn't always great when faced with simple, random questions. On the other hand, human experts aren't always that useful, either — or they are far away and out of reach, sitting behind a wall of required metadata, minimum editorial quality, site-dependent culture, and etiquette!
I guess my very cynical conclusion would be:
Don't trust Wikipedians Stack Exchangers humans. Trust machines even less.
The illustration opening this post is what Midjourney gave me after a couple variations over this prompt:
“A photorealistic illustration of a sentient android competing against a team of human experts, dystopic setting, cyberpunk style, highly detailed”